
Agentic AI in APAC: Navigating the Path from Pilot to Production
This blog post is a follow-up to what I shared at our recent meetup organized by AI Verify, where over 100 members of our community joined us at IMDA to share and learn real-world stories about making Agentic AI reliable.
The Asia-Pacific region is witnessing a significant shift in how organizations approach artificial intelligence, moving beyond traditional AI implementations toward more autonomous, agentic systems. Based on our recent pilot programs with enterprise customers across APAC, we’re seeing distinct patterns emerge in adoption strategies, use cases, and implementation challenges.
Current Adoption Patterns: What Our Pilot Data Reveals
Our customer pilot programs have provided valuable insights into how organizations are actually utilizing agentic AI capabilities. The data reveals interesting trends in feature adoption:
Tool Usage leads the way at 45% adoption, indicating that organizations are primarily leveraging AI agents’ ability to interact with existing software tools and APIs. This suggests a pragmatic approach where companies are extending their current technology stack rather than replacing it entirely.
Multi-Agent Systems follow at a notable 70% adoption rate, demonstrating strong interest in deploying multiple specialized agents that can collaborate on complex tasks. This high adoption rate indicates that APAC organizations recognize the value of distributed AI capabilities.
Reflection capabilities show 15% adoption, suggesting that while organizations value AI systems that can self-evaluate and improve their responses, this remains a more advanced feature that requires additional organizational maturity.
Action-oriented implementations currently represent 5% of adoption, indicating that while there’s interest in AI systems that can take direct actions, most organizations are still in the monitoring and recommendation phase. This low adoption rate reflects the preference for human-in-the-loop approaches, where AI agents recommend actions but require human approval before execution, ensuring oversight and control over critical business decisions.
Top 5 Use Cases Driving APAC Adoption
1. Software Development Lifecycle (SDLC)
Organizations are implementing agentic AI to automate code review processes, generate test cases, and assist in deployment pipelines. The ability of AI agents to understand context across multiple development phases makes them particularly valuable for streamlining software delivery.
2. Deep Research and Analysis
Companies are deploying AI agents to conduct comprehensive market research, competitive analysis, and regulatory compliance reviews. These agents can process vast amounts of unstructured data and synthesize findings across multiple sources and languages—particularly valuable in APAC’s diverse regulatory landscape. For example, financial institutions are using AI agents to research source of wealth documentation and process commercial loan company profiles, automatically gathering and analyzing corporate filings, news articles, and regulatory records to build comprehensive risk assessments.
3. Manufacturing Process Automation
Manufacturing companies are using agentic AI to optimize production schedules, predict maintenance needs, and coordinate supply chain activities. AI agents can adapt to changing production requirements and coordinate across multiple systems in real-time. A notable application is in new product design research, where AI agents analyze market trends, competitor products, regulatory requirements, and technical specifications to provide comprehensive insights that inform product development decisions and accelerate time-to-market.
4. Sales Insights and Customer Experience
Organizations are implementing AI agents to analyze customer interactions, predict purchase behavior, and personalize engagement strategies. These systems can process customer data across multiple touchpoints and provide actionable insights for sales teams.
5. Procurement Process Automation
Companies are streamlining procurement workflows using AI agents that can evaluate suppliers, negotiate contracts, and manage purchase orders. These agents can adapt to changing market conditions and organizational requirements while maintaining compliance standards.
Three Distinct Adopter Profiles
Our experience across APAC markets has revealed three primary adoption patterns:
Early Adopters: The “Agentic” Pioneers
These organizations are enthusiastic about becoming “agentic” and focus on automating existing workflows. They’re willing to experiment with newer technologies and often serve as proof-of-concept environments for more advanced AI capabilities. Early adopters typically have strong technical teams and leadership buy-in for AI initiatives.
Stack Builders: Long-term Strategic Planners
Stack Builders approach agentic AI with enterprise-wide adoption in mind. They start with simple, well-defined use cases while building the infrastructure and organizational capabilities needed for broader deployment. These organizations prioritize scalability and integration with existing enterprise systems.
Pragmatic Adopters: Embedded Solution Seekers
Pragmatic adopters prefer implementing agentic AI through embedded applications in platforms they already use, such as Salesforce or Microsoft 365. They focus on immediate business value and prefer solutions that require minimal change to existing processes and user behavior.
Key Implementation Challenges
Despite growing interest, organizations face several significant hurdles in scaling agentic AI implementations:
Business Readiness for Dynamic Workflows
Traditional business processes are designed for predictability and control. Agentic AI introduces dynamic decision-making that can feel unpredictable to stakeholders. Organizations struggle with the cultural shift required to trust AI agents with important business decisions, particularly in risk-averse cultures common across many APAC markets.
Quantification of Business Outcomes
Measuring the ROI of agentic AI implementations remains challenging. Unlike traditional automation projects with clear metrics, agentic systems often provide value through improved decision quality, faster response times, and enhanced adaptability—benefits that are difficult to quantify using conventional business metrics.
Access to Source Systems
Many organizations have data and systems scattered across multiple platforms, often with limited API access or integration capabilities. Agentic AI requires comprehensive data access to function effectively, but legacy systems and data silos create significant technical barriers to implementation.
Cost of Manual Data for Evaluation
Evaluating agentic AI performance requires significant manual effort to create test datasets, validate outputs, and assess decision quality. Organizations underestimate the ongoing cost of maintaining evaluation frameworks, particularly when AI agents are deployed across multiple use cases with different success criteria.
Looking Forward: The Path to Maturity
The APAC market’s approach to agentic AI reflects broader regional characteristics: thoughtful adoption, emphasis on practical business outcomes, and careful risk management. Organizations that succeed in scaling agentic AI implementations will likely be those that address the fundamental challenges of trust, measurement, and integration while building organizational capabilities for managing dynamic AI systems.
Two critical factors will determine scalability success: agent observability and cost optimization. Agent observability—the ability to monitor, debug, and understand AI agent decision-making processes in real-time—is essential for building organizational trust and ensuring reliable performance at scale. Without clear visibility into how agents make decisions, organizations struggle to troubleshoot issues, optimize performance, and maintain compliance standards.
Equally important is managing the cost of the solution, which becomes a key barrier to scale. While pilot programs may absorb higher per-token costs, enterprise-wide deployment requires sustainable economic models. Organizations need to factor in not just the direct costs of AI infrastructure, but also the ongoing expenses of monitoring, evaluation, human oversight, and system integration.
As the technology matures and more organizations share their implementation experiences, we expect to see standardized evaluation frameworks, improved integration capabilities, and greater organizational comfort with AI-driven decision-making. The current pilot phase is laying the groundwork for more widespread adoption across the region.

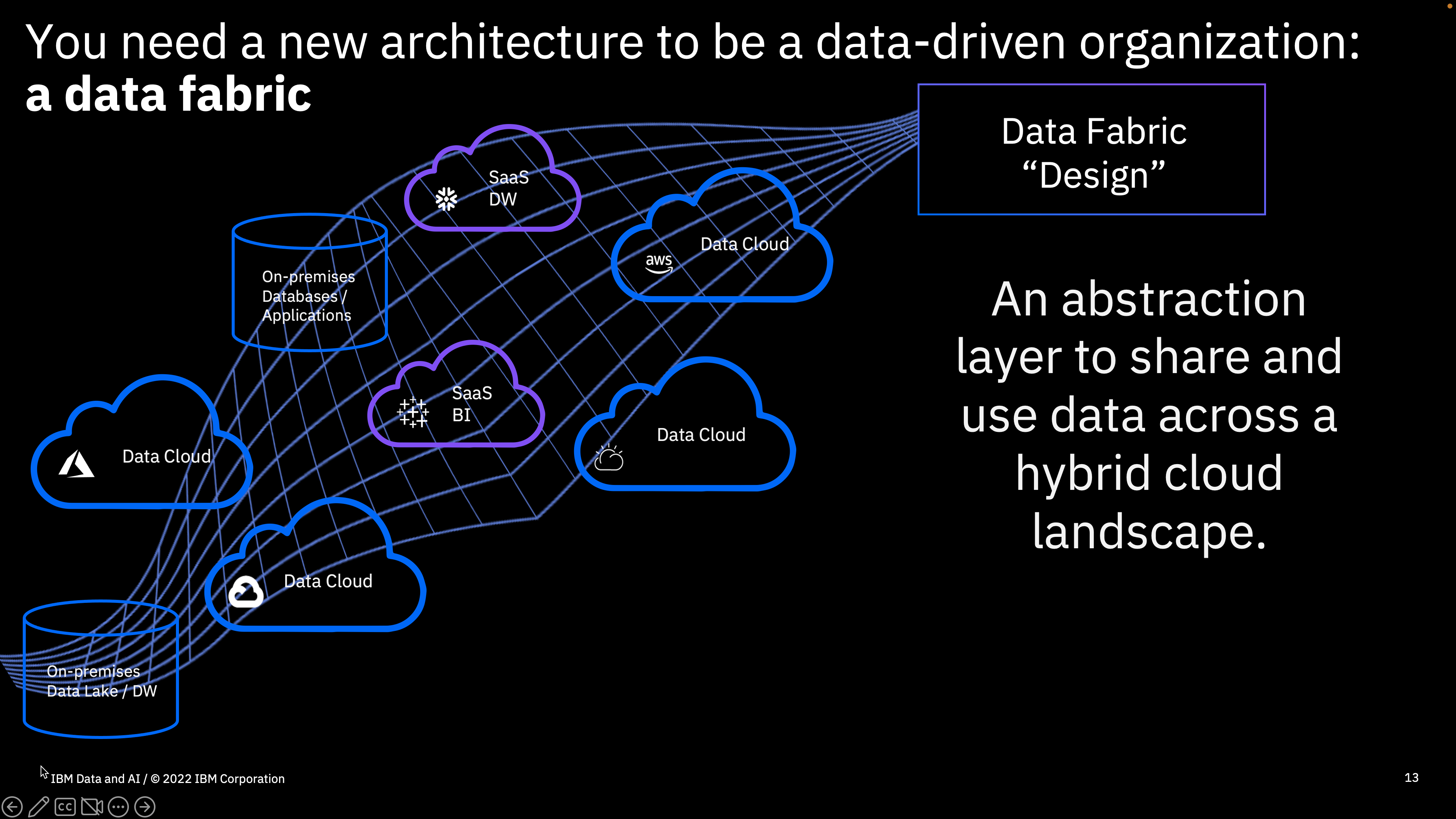




 With GDPR regulation acting as a catalyst, every government is addressing the export of personal data outside the country and on data collection intent & mechanism. This has suddenly changed the data architecture deployment landscape and specifically for large enterprises who were trying to consolidate data ( data lake initiatives) and create a Center of Excellence of data science team in order to gain strategic advantage in there journey toward a “data-driven organization”. The reality for most of the multi-national organization will be a hub and spoke data architecture. With “Data Scientist” skills already being in high demand replicating workforce at each site is not feasible. Further, with multi-site data collection standardization on common processes and tools is operationally challenging. The problem is further magnified with multiple tools and multi-cloud deployment.
With GDPR regulation acting as a catalyst, every government is addressing the export of personal data outside the country and on data collection intent & mechanism. This has suddenly changed the data architecture deployment landscape and specifically for large enterprises who were trying to consolidate data ( data lake initiatives) and create a Center of Excellence of data science team in order to gain strategic advantage in there journey toward a “data-driven organization”. The reality for most of the multi-national organization will be a hub and spoke data architecture. With “Data Scientist” skills already being in high demand replicating workforce at each site is not feasible. Further, with multi-site data collection standardization on common processes and tools is operationally challenging. The problem is further magnified with multiple tools and multi-cloud deployment.





