As the year starts we will see plethora of reports on the trend for 2016. The reports are based on numerical analysis and lots of fact findings. However we all have our own gut feeling…here is what I see for Big Data and Analytics. This is primarily for Asia Pacific market and totally my personal opinion.
1. Focus on Data Acquisition.
In past two years early adopters have invested in Big Data Platform, however still far away from real bite of “big data Analytics”. Data Acquisition would be key for them to fulfill that promise. This is more than just social data acquisition. Am seeing demand for “Data Refinery” such as Location Based Data, Demographic Information, Spending habit etc. A great opportunity for startup. Not to forget weather data
2. Spotlight back on Data Integration tools.
Scripting is powerful, faster and fun. Sounds “cool” when kicking off the big data initiative. However that fun doesn’t last longer and am seeing spotlight back on big data Integration tools. Would safely predict that all those who invested in big data Platform would be spending on data integration tool this year.
3. One of the Hadoop Vendor would get acquired by end of 2016.
This may sound coming from nowhere, but shouldn’t be surprising looking at the financial sheet for most of the pure Hadoop Vendor. In all probability am seeing one of the Hadoop vendor getting acquired by end of this year.
4. Cloud becoming the primary deployment model for Analytics.
Business demand for agility (in action) and technology to cater “data privacy “would make Cloud as Primary model for Analytics Infrastructure.
F1, Spark and Blu-ray Player
What does F1, Spark and Blu-Ray player have in common? Before you start browsing your “intellectual” thoughts, let me state the fact, it just happens to be few regular events in last week. I hosted a session on Apache Spark, attended the SIA F1 weekend event and picked up my free “Blu-Ray” Player (gift with my TV upgrade).
Back to work, and while reflecting on various advises and feedback on Big Data Analytic Deployments, it seems these dis-joint events actually represents today Analytics ecosystem and processes.
While F1 represent the ultimate Speed and Agility. Apache Spark promises to bring the same “Speed and Agility” to Big Data analytics.
F1 relies on discipline and rigor, and the key to winning is to adjust, adapt, and realign during the race (execution) itself. Big Data Analytics success factors are same. It’s not about starting with a KPI driven big-bang and rigid data governance approach. The key to “Big Data” Analytic is to start with a minimal investment, business aligned focused goal and adjusting, adapting and re-aligning during the development life-cycle itself.
Apache Spark promises great Agility in terms of Big Data Analytic development life-cycle. It provides ability to create complete data science workflow, ingest, transform, prepare data, execute analytic algorithm, analyze and visualize all on a single Platform. A unified Platform for such development allow to rapidly adjust, adapt and re-align and thus promises to provides Business with Insights and Agility they have been seeking.
What about the speed? While SPARK hold the record for quickly sorting 100 TB of data (1 trillion records) , its improving similar to Mercedes engine for F1 cars by each release.

What about the “Blu-Ray” Player ? While the “Blu-Ray” Player is one of the excellent technology,I have been struggling to understand it relevance in my house. I watch Movies on Apple Tv , its agile ( I can decide at any time what to watch, change my preference , pay and enjoy). I use USB-Drive/external Drive for any of my existing content. I don’t see a reason why I should be paying for costly “Blu-ray” Disc, which forces me to limit my choice and loose flexibility.
The last statement just reflects the comment I have been hearing from Business Leaders about the value they see from there “traditional data warehouse” approach.
Add to this, the Disc and Blu-ray Region code map, (data governance going wrong) which again limits what I can play, its excellent technology but today irrelevance to me.
So what’s represents yours Analytic Ecosystem? “Speed and Agility” or “High Cost and Rigid” ?
Lambda Architecture and my experience with IBM Big Data Reference Architecture
Recently, few of my clients have been showing a keen interest on Lambda Architecture for big data applications. What was surprising was that lots of feedback came on how it is a new paradigm and would change how big data applications are designed.
Well, even though with SPARK evolution, building an Analytic application involving real time and batch processing is getting more popular, the architecture has been practiced over the years at least at IBM. While I personally feel that as SPARK evolves & becomes successful it would bring the real simplicity in deployment for Lambda Architecture and make it more popular.
I wanted to share my experience leveraging IBM Big Data Reference Architecture for applications involving both batch and real time processing. For a moment Replace Hadoop with a Data Warehouse database and Lambda architecture looks very familiar. Few common use case we have been deploying over several years has been in Telco where Infosphere Stream pick the incoming CDR(call details record), does the on the fly data conversion such as de-duplication and write the data into a warehouse and in parallel process the data for aggregation based on time, event etc. to generate real time views. Some of this real time analysis (views) was synch to data warehouse and you have the single Serving Layer.
Later with Hadoop popularity we evolved the architecture to dump the original data to Hadoop, while stream was processing it in parallel, writing some of the aggregated view to warehouse or Hadoop itself. With Infosphere Stream capability to directly read and write to HDFS as well as any database, the deployment is more simplified. This also ensured simplicity as the batch re-computing can be done at the stream layer itself without need to write separate code at Hadoop layer.
I hope this gives some perspective to existing Streams Developers that they have embraced the right technology and tools much ahead of time.
References:
Lambda Architecture Overview: http://lambda-architecture.net/
IBM Big Data Reference Architecture:
http://channelbigdata.com/video/reference-architecture-for-big-data-and-the-data-warehouse-part-2
Data Lake for the Enterprise: Using Elasticity of Cloud and Safety of In-premises deployment
We experienced this on every Analytics/Data Warehousing project that a disproportionate portion of the time spent is about data preparation i.e acquiring /preparing /formatting/normalizing the data. As as the use of Analytics mature in an organisation, dimensional modelling and KPI based reporting are becoming old-fashioned and of limited use. Subject matter experts want access to their organisation’s data to explore the content, select, control, annotate and access information using their terminology with a frameowrk of data protection and governance. We saw the conflict between business and IT operations for democratisation of data and operational control. Thus the concept of Data Lake started evolving.
Data lake as understood by most of the enterprise is a big data repository that provides data to an organization for a variety of analytics processing including:
- Discovery and Exploration of Data.
- Simple Ad Hoc Analytics.
- Complex analysis for business decisions.
- Real time Analytics & Reporting.
It is possible to deploy analytics into the data lake to generate additional insight from the data loaded into the data reservoir. There are two aspect of building an effective Data Lake, Platform Infrastructure and data flow ( includes governance and control aspect). While am not touching on the data flow here, would just like to caution that just considering a very structured multi-dimensional modelling on a data lake itself takes away the objective of data lake.
So on the platform aspect for a data lake, Hadoop is becoming synonymous with data lake project and in fact evolved due to it. Most of the vendor today either have a cloud solution for Hadoop or an appliance based approach. While Cloud provides elasticity it’s still a challenge for most of the enterprise to move all sorts of data freely on cloud. In-premise Appliance based approach provide simplicity however looses the elasticity required for a data lake.
Here I suggest a hybrid model which provides both elasticity as well as safety net required for most of the enterprise. A small hadoop cluster in-premises provides safety to collect and store all “data asset” specifically from your in-house applications. It can work as a staging area for volumes of data and analytics area for your confidential data. Can avail cloud hadoop deployment for massive transformation and deeper analytical algorithm and scale (shrink or grow as required). In order to maintain the integrity and data security you need a secure data movement, encryption and access control.
Here is a suggested Architecture based on IBM Big data portfolio.
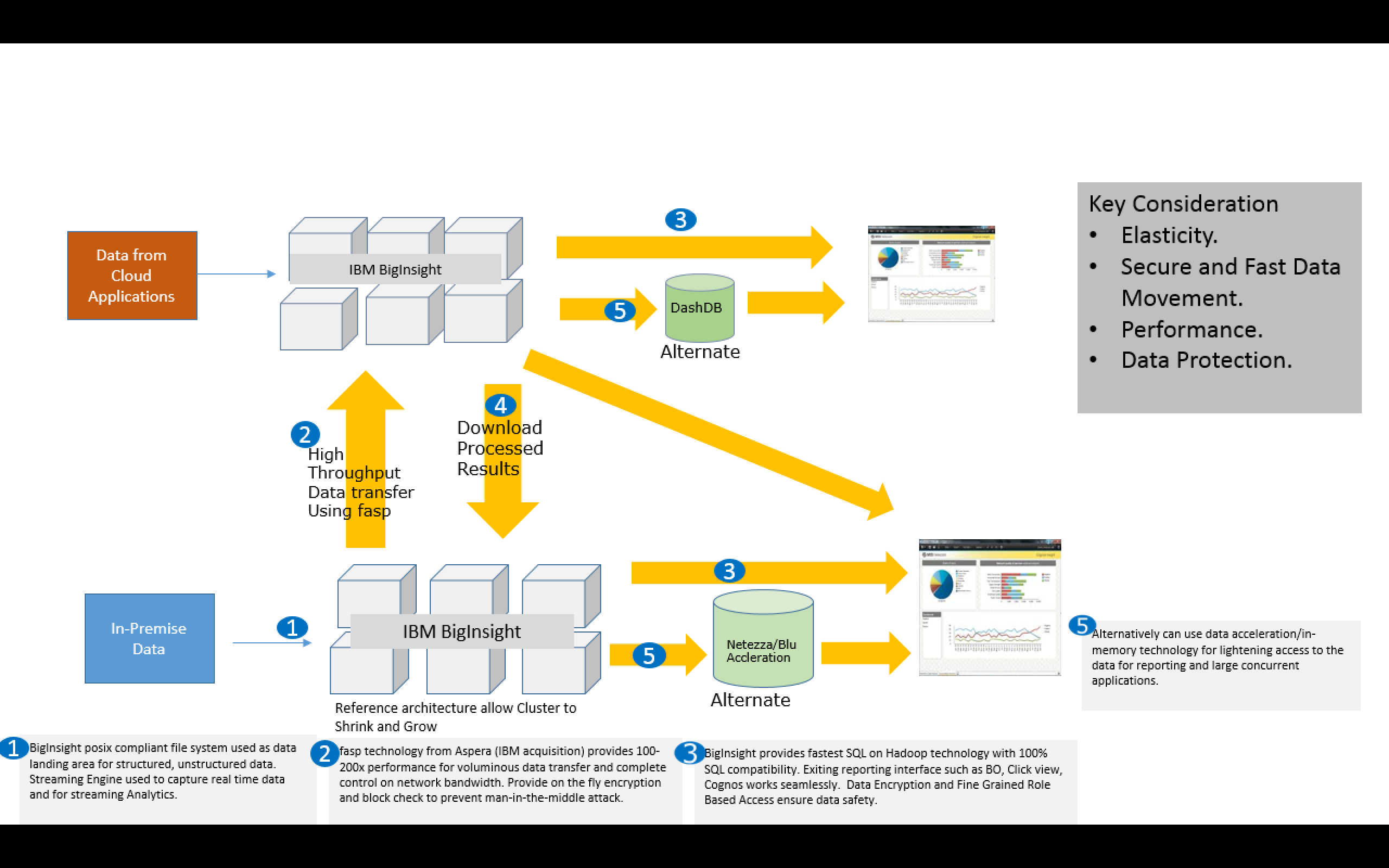
Hybrid Enterprise Data Lake Architecture
IBM Reference Architecture for BigInsight( hadoop ) provides the flexibility to deploy secure in-premise cluster of any size and cloud offering for BigInsight ( either as PaaS, SaaS, IaaS) helps to provide elasticity.
The above architecture really opens up un-explored opportunities without having to deal with a big time initial investment, changing business dynamics & analytics requirement , foremost without compromising on the control. Business can choose to experiment with setting up a data lake with a in-premise cluster , and let the usage of analytics evolve. As and when they are ready can provision a cloud for any specific analysis they prefer to do. ( Example Click data analysis for traffic generated on the web for retailers during the holiday season or multi-facet clustering for a new promotion by a financial hub).
While the SQL on Hadoop has evolved for structured data , use of existing MPP/In-memory technologies as accelerator for operational reporting is optional. Will publish my thoughts on data flow and governance model for data lake in my next blog.
MPP grade perfromance for data warehouse on Hadoop
Does below explain plan sounds business as usual……..What if i say that’s a plan for a query executed on Hadoop.
IBM announced BigInsight 3.0 with new BigSQL capability that would not use map-reduce for SQL kind of workload still leverage hdfs for data files. This is like leveraging best of Hadoop architecture for lower cost, scalability and MPP architecture for Performance.

Here is a some detail information about it. I will post my next blog experiencing security and performance for a actual workload. Keep tuned.
Securing a Hadoop Cluster
Drafted this while responding to a customer query…thought this would be useful for others as well.
This draft summarizes the security available with BigInsight with specific emphasis on BigSQL. The Security concept is true for other Hadoop flavour as well.
Authentication :
When users log in to the InfoSphere® BigInsights™ Console, if their credentials are validated, they gain access to InfoSphere BigInsights Console functionality based on role membership. Three types of authentication are supported: flat file, LDAP and PAM.
1. Flat file
Password encryption with hex or Base64 encodings is supported. The digest encoding is valid only if the digest algorithm is specified. If the digest algorithm is specified and the digest encoding is not specified, the default hex encoding is assumed. If a digest algorithm is not specified, it is assumed that passwords are stored in plain text.
2. LDAP
If you choose LDAP authentication during installation, you configure the InfoSphere BigInsights Console to communicate with an LDAP credential store for users, groups, and user to group mappings.
3. PAM
If you choose PAM authentication during installation, when a user accesses the InfoSphere BigInsights Console, the username and password are passed to the InfoSphere BigInsights PAM module.
You can also use PAM with LDAP so that when a user logs in, InfoSphere BigInsights communicates with your PAM module, and then your PAM module communicates with your LDAP server to authenticate users.
Authentication for Big SQL
Big SQL uses the BigInsights Console to authenticate users .
Authorization
BigInsights supports four predefined roles. For each role, there is a set of actions that can be performed in the cluster.
• BigInsightsSystemAdministrator. – Performs all system administration tasks. Forexample, a user in this role can perform monitoring of the cluster’s health, and adding,removing, starting, and stopping nodes.
• BigInsightsDataAdministrator. -Performs all data administration tasks. For example, these users create directories, run Hadoop file system commands, and upload, delete, download, and view files.
• BigInsightsApplicationAdministrator. -Performs all application administration tasks, for example publishing and unpublishing (deleting) an application, deploying and removing an application to the cluster, configuring the application icons, applying application descriptions, changing the runtime libraries and categories of an application, and assigning permissions of an application to a group.
• BigInsightsUser, -Runs applications that the user is given permission to run and views the results, data, and cluster health. This role is typically the most commonly granted role to cluster users who perform non-administrative tasks.
Authorisation for the Big SQL server
The authorization modes use the Hadoop-based Distributed File System (HDFS) permissions to control data access.
• none
Using the none authorization mode means that all operations inside the Big SQL server are done using a super-user or admin user authority, regardless of which user is connected to the server. This mode is typically used when security is not much of a concern, such as with test systems.
• dataSource
In the dataSource mode, if the currently connected user is an admin, then the Big SQL server uses the same user ID as the Big SQL server process owner, typically biadmin, to perform the Reading, Writing to HDFS and Spawning a map-reduce jobs.
If the currently connected user is not an admin, then the above operations are performed using the currently connected users’s user ID. For example, a user with user ID user1 can query a table if user1 had read permission for schema-directory, table-directory, and table-files via the owner’s, group’s, or other’s read permission.
Users can share or restrict the data access by changing the HDFS ownership and HDFS permissions of the table schema directory. All users who connect to the Big SQL server must have a valid user login to the Big SQL server. All users also need an entry in the InfoSphere® BigInsights™ Console for one of the authentication mechanisms: no-security, flat-file security, LDAP, or PAM. This entry provides the Big SQL server with the user ID and password for the relevant users.
If two users share a table in such a way that user-1 creates the table and user-2 loads the data into the table, then user-2 requires the write permission on the parent directory for the table. After the table data is loaded, the table is owned by user-2. If user-1 must own the table, then user-2 can change the permission on the table to make user-1 the owner of the table.
Similarly users can be restricted to access a particular tables . A snapshot below for access denied.
Accounting
InfoSphere BigInsights stores security audit information as audit events in its own audit log files for general security tracking. As part of core Hadoop, HDFS and MapReduce provide basic audit report. Additionally, You can configure InfoSphere BigInsights to send audit log events to InfoSphere Guardium for security analysis and reporting. After InfoSphere BigInsights events exist in the InfoSphere Guardium repository, other InfoSphere Guardium features such as workflow to email and track report signoff, alerting, and reporting are available.
The security audit information that InfoSphere BigInsights generates depends on your environment. The following list is representative of the type of information that InfoSphere BigInsights generates:
Hadoop Remote Procedure Calls (RPC) authentication and authorization successes and failures
• Hadoop Distributed File System (HDFS) file and permission-related commands such as cat, tail, chmod, chown, and expunge
• Hadoop MapReduce information about jobs, operations, targets, and permissions
• Oozie information about jobs
• HBase operation authorization for data access and administrative operations, such as global privilege authorization, table and column family privilege authorization, grant permission, and revoke permission
Data Protection
Data protection ensures privacy and confidentiality of information.
• The InfoSphere BigInsights installer provides the option to configure HTTPS to potentially provide more security when a user connects to the BigInsights web console. If HTTPS is selected, the Secure Sockets Layer and Transport Layer Security (SSL/TLS) protocol provides security for all communication between the browser and the web server.
• We can enable SSL encryption for the data exchange between clients and the IBM Big SQL server.
• Basic Authentication support for HttpFS server. (Hadoop HDFS over HTTP).
Summary
The InfoSphere® BigInsights™ security architecture includes authentication, roles and authorization levels, HTTPS support for the InfoSphere BigInsights console, and reverse proxy.
Most convincing Big Data Use cases in Enterprise for 2013
Most convincing Big Data Use cases in Enterprise
Since last 12 months visited around 10 countries and had several web-conference with established enterprises around the world.( Except America and Europe). Everyone has been eager to understand big data and start journey with the most profitable use cases. However all enthusiasm doesn’t kicks up a big data project as the toughest job has been to identify relevant use cases that would make them profitable. Only few customers consider big data for optimizing operational cost, most of them tend to explore how they can create a new service, products, or optimize customer experience using Big Data technologies. Here are the top 5 use cases that were most convincing.
- URL Log, xDR , IPDR Analysis by Telco.
- Data warehouse Augmentation for Bankers.
- Network Inspection, Security and Audit across verticals.
- Product Quality /Defect Tracking for Manufacturing.
- Search across several terabytes of information.
Well the most discussed use case has been Social Media Analytics for understanding customer buying pattern, sentiment analytics. However after few rounds of discussion it becomes challenging to justify the tangible benefit and ROI. Also considering the data availability, veracity and availability of point tools and lack of Strategy around social media made this a challenging one to get started.
