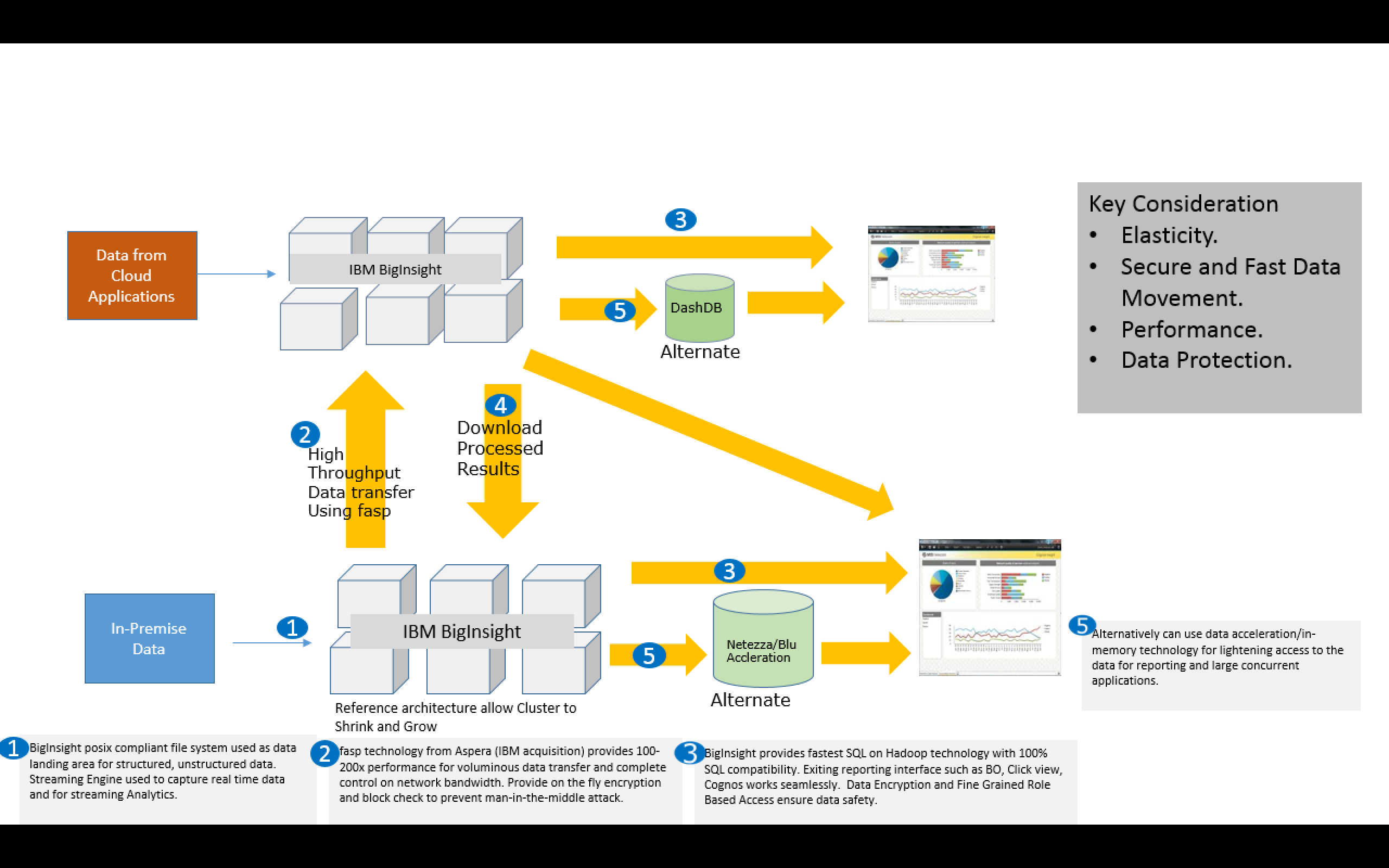
What does F1, Spark and Blu-Ray player have in common? Before you start browsing your “intellectual” thoughts, let me state the fact, it just happens to be few regular events in last week. I hosted a session on Apache Spark, attended the SIA F1 weekend event and picked up my free “Blu-Ray” Player (gift with my TV upgrade).
Back to work, and while reflecting on various advises and feedback on Big Data Analytic Deployments, it seems these dis-joint events actually represents today Analytics ecosystem and processes.
While F1 represent the ultimate Speed and Agility. Apache Spark promises to bring the same “Speed and Agility” to Big Data analytics.
F1 relies on discipline and rigor, and the key to winning is to adjust, adapt, and realign during the race (execution) itself. Big Data Analytics success factors are same. It’s not about starting with a KPI driven big-bang and rigid data governance approach. The key to “Big Data” Analytic is to start with a minimal investment, business aligned focused goal and adjusting, adapting and re-aligning during the development life-cycle itself.
Apache Spark promises great Agility in terms of Big Data Analytic development life-cycle. It provides ability to create complete data science workflow, ingest, transform, prepare data, execute analytic algorithm, analyze and visualize all on a single Platform. A unified Platform for such development allow to rapidly adjust, adapt and re-align and thus promises to provides Business with Insights and Agility they have been seeking.
What about the speed? While SPARK hold the record for quickly sorting 100 TB of data (1 trillion records) , its improving similar to Mercedes engine for F1 cars by each release.

What about the “Blu-Ray” Player ? While the “Blu-Ray” Player is one of the excellent technology,I have been struggling to understand it relevance in my house. I watch Movies on Apple Tv , its agile ( I can decide at any time what to watch, change my preference , pay and enjoy). I use USB-Drive/external Drive for any of my existing content. I don’t see a reason why I should be paying for costly “Blu-ray” Disc, which forces me to limit my choice and loose flexibility.
The last statement just reflects the comment I have been hearing from Business Leaders about the value they see from there “traditional data warehouse” approach.
Add to this, the Disc and Blu-ray Region code map, (data governance going wrong) which again limits what I can play, its excellent technology but today irrelevance to me.
So what’s represents yours Analytic Ecosystem? “Speed and Agility” or “High Cost and Rigid” ?