
Over the last few months, I’ve had dozens of conversations with CIOs, CTOs, and CDOs across banking, government, telecom, healthcare, and other large enterprises.
Despite all the attention around generative AI and agentic AI, the sentiment among technology leaders is still surprisingly divided.
I generally see two very different camps.
One group, especially in highly regulated industries, remains deeply skeptical. They are cautious for good reason. Concerns around security, governance, compliance, and trust are still very real.
The other group wants to move faster, but they are overwhelmed. The pace of innovation is relentless. New models, tools, frameworks, and platforms keep appearing almost every week. For many leaders, the challenge is not whether AI matters. It is deciding where to begin, what to prioritize, and how to move without creating unnecessary risk or wasted investment.
Both perspectives are understandable. But they highlight the same underlying issue.
The hype around AI has not translated easily into enterprise adoption.
The missing piece for many organizations is a clear roadmap for how AI adoption should progress inside an enterprise environment.
The Skepticism: “Is Agentic AI Even Real?”
Many CTOs in highly regulated industries are questioning whether agentic AI is practical today.
Their concerns are legitimate. They see:
- AI systems behaving like black boxes
- Security risks in autonomous agents
- Lack of explainability
- Unclear governance models
For organizations operating under strict regulatory frameworks, this raises a simple but critical question: Is this technology mature enough to trust with critical business processes? Because of these risks, many leaders are not pursuing incremental improvements.
Instead, they are waiting for a large breakthrough use case that justifies the risk of adoption.
But this expectation can delay meaningful progress.
The Reality: Agentic AI Does Not Mean Full Autonomy
One of the biggest misconceptions about agentic AI is that it must behave like a fully autonomous system, similar to self-driving cars.
We are not there yet.
And more importantly:
Enterprise AI does not require full autonomy to create business value.
In practice, the most successful implementations today operate at different levels of autonomy.
Narrow-Scope Agents
These agents operate with:
- defined tools
- limited decision boundaries
- structured workflows
Architecturally, they behave more like intelligent backend services.
This approach provides something enterprises care deeply about: behavioural consistency and predictability.
In many organizations, these types of agents already deliver meaningful benefits in areas such as:
- workflow automation
- engineering productivity
- operational support
More Autonomous Agents
In low-risk domains such as knowledge management or internal assistance, agents can operate with greater autonomy.
Examples include:
- research assistants
- internal knowledge agents
- productivity assistants
These systems tolerate more variability because the risk profile is lower.
One reason agentic AI has been over-hyped is that some vendors promote the idea of a single universal agent platform doing everything.
In reality, enterprise AI architectures will likely consist of multiple agents with varying levels of autonomy, each designed for specific use cases.
The Other Dilemma: “We Want to Start, But the Investment Looks Massive”
The second group of leaders I meet are enthusiastic about AI but overwhelmed by the perceived cost.
They see rapid advances in:
- models
- infrastructure
- frameworks
- tooling
And they worry that by the time they make a large investment, the technology may already be obsolete.
This fear often leads to analysis paralysis.
But the reality is much simpler.
You do not need massive upfront investment to begin the enterprise AI journey.
In fact, large “big bang” AI initiatives often fail.
The more practical approach is straightforward:
- Identify a real business problem
- Run a targeted experiment
- Deploy the solution in production
- Expand once the value is proven
AI adoption works best when it follows an iterative maturity journey, not a single transformation program.
Why Early Copilot Promises Didn’t Always Deliver
Another frustration I frequently hear relates to the early wave of AI copilots.
Many organizations expected dramatic productivity gains.
But the outcomes were mixed.
That is because most copilots focused on individual productivity, such as:
- email summarization
- document drafting
- search assistance
While useful, these improvements do not necessarily translate into enterprise-level ROI.
The deeper productivity gains come from something else entirely:
the readiness of enterprise systems behind the AI.
Enterprise-level AI productivity requires:
- integrated enterprise data
- modern application architectures
- strong security models
- governance frameworks
What works for general productivity use cases does not automatically translate to enterprise environments.
In many cases, organizations rushed to become “GenAI ready” without first ensuring their enterprise platforms were AI ready.
.
A Practical Approach: Start Small, Scale Intelligently
The organizations that succeed with AI are not the ones chasing every new breakthrough.
They are the ones who:
- start with real business problems
- validate outcomes through experimentation
- deploy incrementally
- scale once value is proven
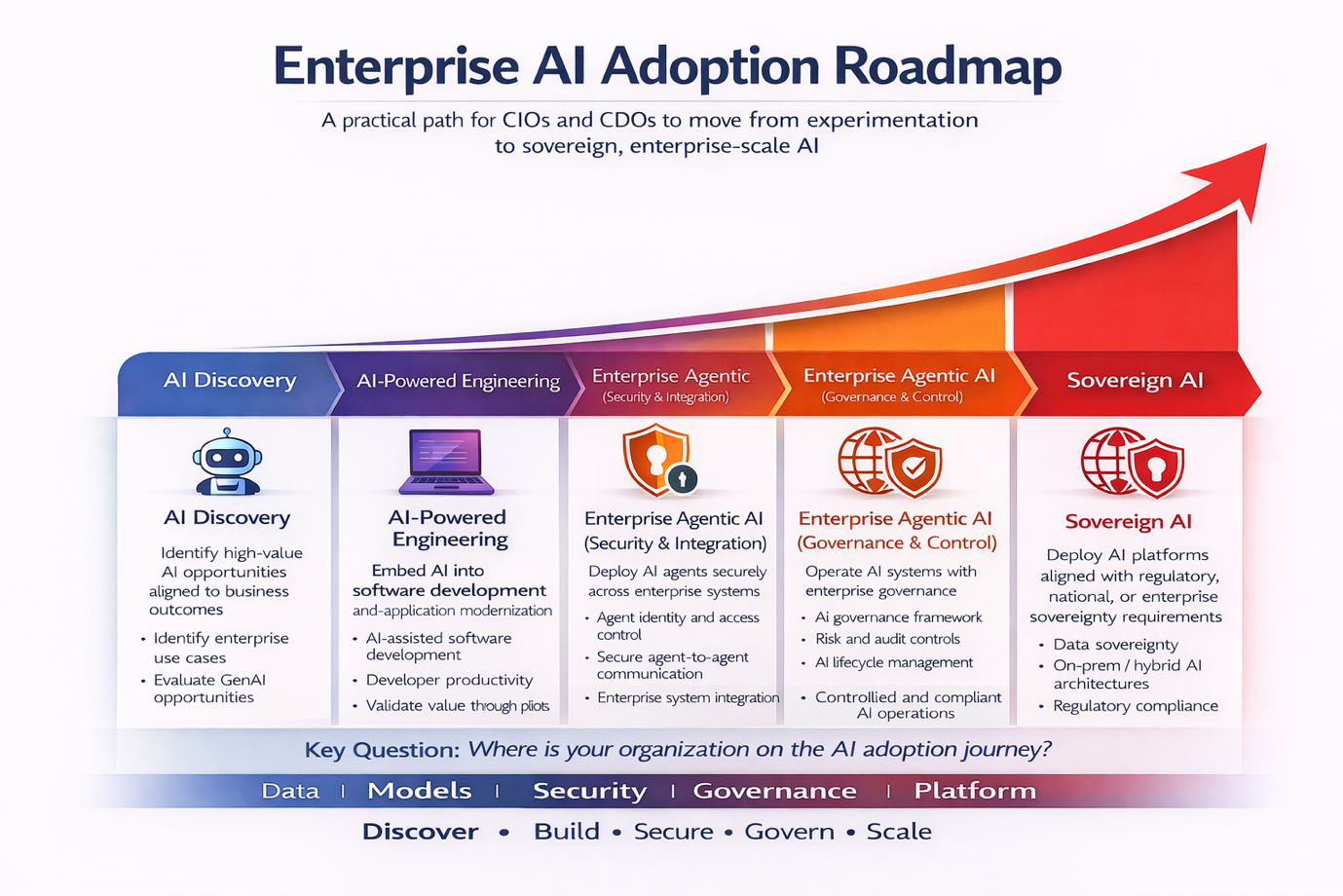
AI adoption is less about technology breakthroughs and more about organizational readiness and disciplined execution.
How IBM Can Help
At IBM, our Client Engineering teams work closely with organizations to navigate this journey.
Rather than starting with technology, we begin with business outcomes and real use cases aligned to your Business transformation Journey.
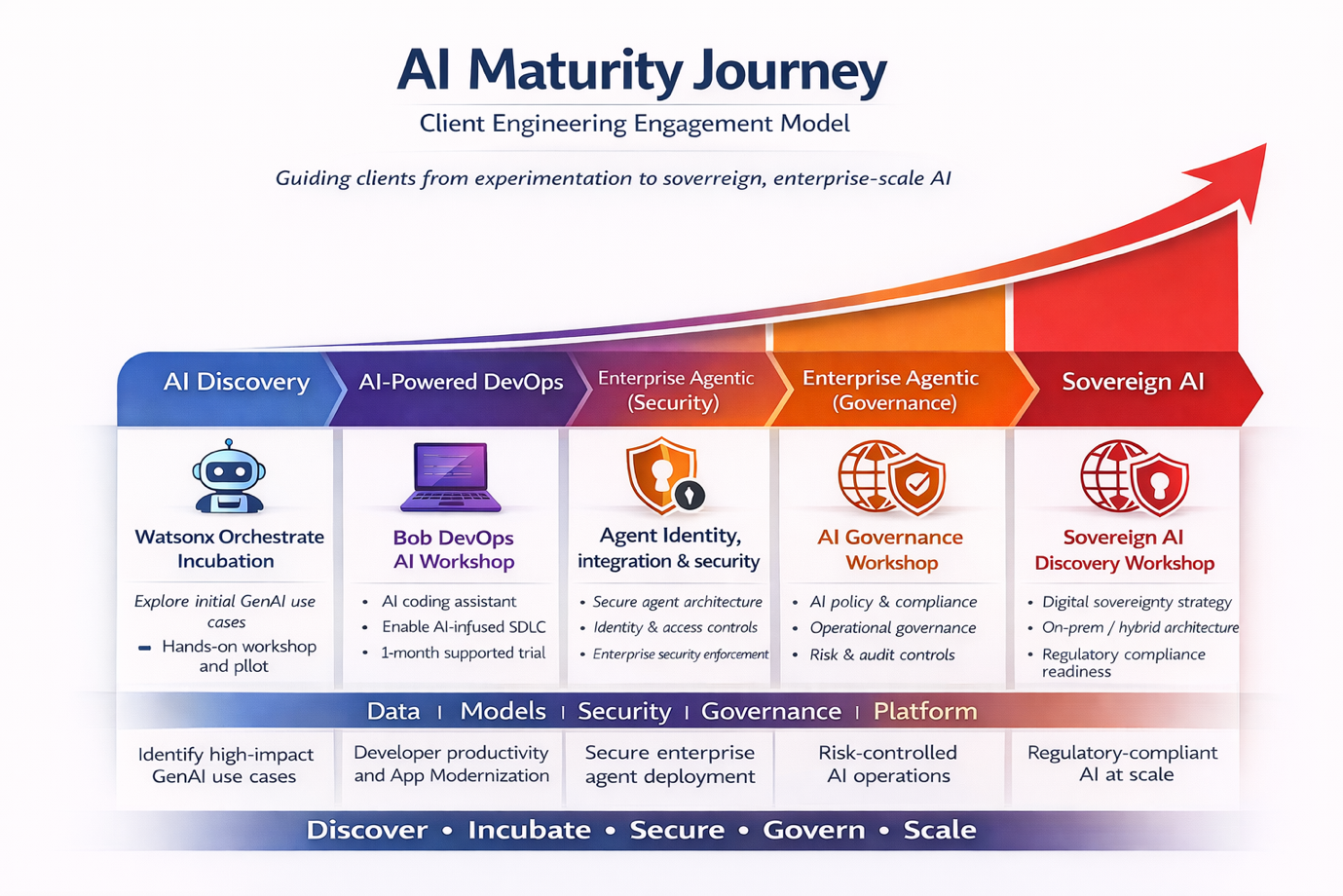
The Key Question for Every CIO and CDO
Every enterprise today is at a different stage of its AI adoption journey.
The real question is not whether AI will transform your organization.
It will.
The more important question is where you are today — and what capability you need to build next to move forward with confidence.
My take is that , the organizations that get that right will move beyond the hype and start realizing real value from AI.
Feel free to reach out if you would like to continue the discussion.

