We experienced this on every Analytics/Data Warehousing project that a disproportionate portion of the time spent is about data preparation i.e acquiring /preparing /formatting/normalizing the data. As as the use of Analytics mature in an organisation, dimensional modelling and KPI based reporting are becoming old-fashioned and of limited use. Subject matter experts want access to their organisation’s data to explore the content, select, control, annotate and access information using their terminology with a frameowrk of data protection and governance. We saw the conflict between business and IT operations for democratisation of data and operational control. Thus the concept of Data Lake started evolving.
Data lake as understood by most of the enterprise is a big data repository that provides data to an organization for a variety of analytics processing including:
- Discovery and Exploration of Data.
- Simple Ad Hoc Analytics.
- Complex analysis for business decisions.
- Real time Analytics & Reporting.
It is possible to deploy analytics into the data lake to generate additional insight from the data loaded into the data reservoir. There are two aspect of building an effective Data Lake, Platform Infrastructure and data flow ( includes governance and control aspect). While am not touching on the data flow here, would just like to caution that just considering a very structured multi-dimensional modelling on a data lake itself takes away the objective of data lake.
So on the platform aspect for a data lake, Hadoop is becoming synonymous with data lake project and in fact evolved due to it. Most of the vendor today either have a cloud solution for Hadoop or an appliance based approach. While Cloud provides elasticity it’s still a challenge for most of the enterprise to move all sorts of data freely on cloud. In-premise Appliance based approach provide simplicity however looses the elasticity required for a data lake.
Here I suggest a hybrid model which provides both elasticity as well as safety net required for most of the enterprise. A small hadoop cluster in-premises provides safety to collect and store all “data asset” specifically from your in-house applications. It can work as a staging area for volumes of data and analytics area for your confidential data. Can avail cloud hadoop deployment for massive transformation and deeper analytical algorithm and scale (shrink or grow as required). In order to maintain the integrity and data security you need a secure data movement, encryption and access control.
Here is a suggested Architecture based on IBM Big data portfolio.
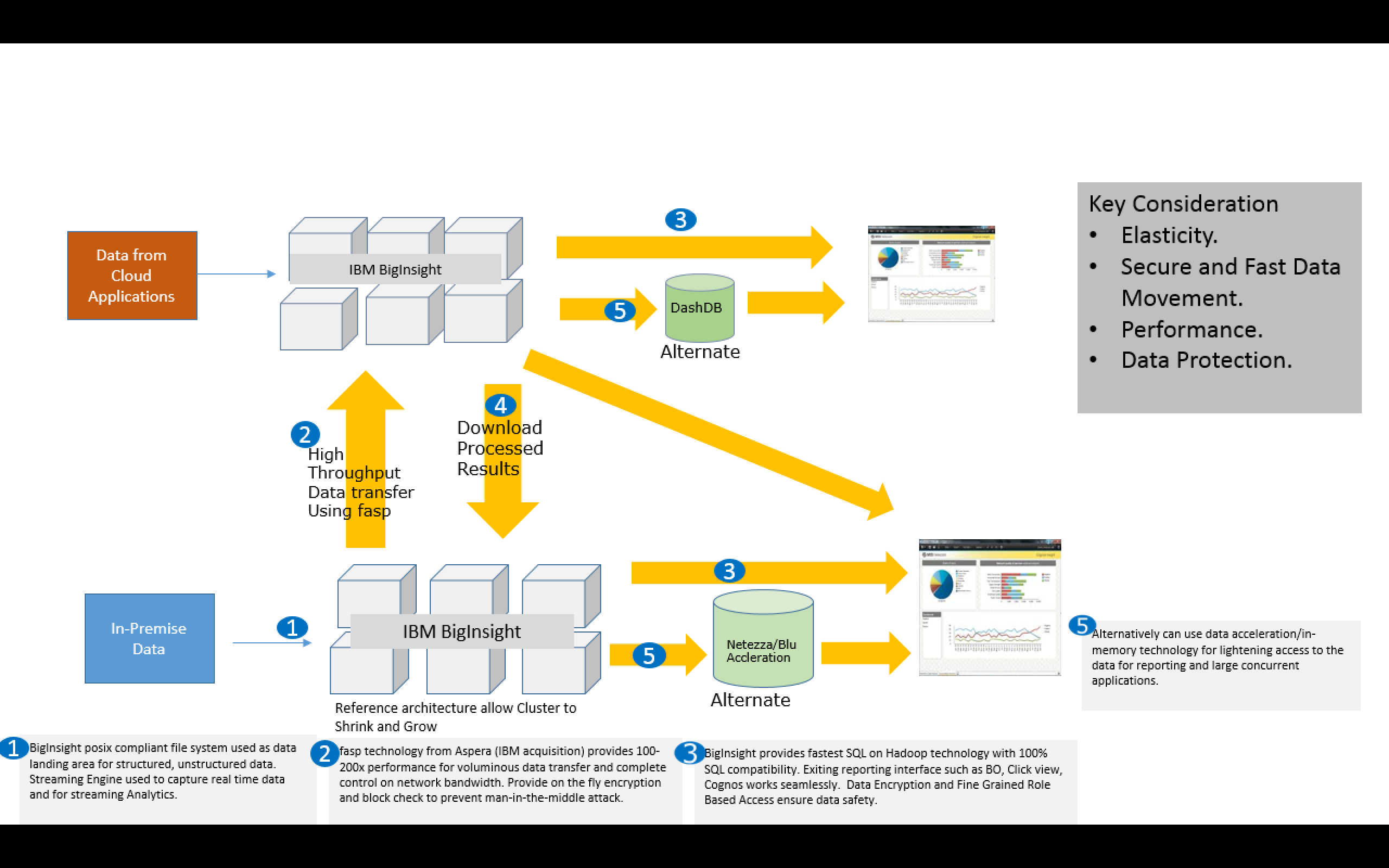
Hybrid Enterprise Data Lake Architecture
IBM Reference Architecture for BigInsight( hadoop ) provides the flexibility to deploy secure in-premise cluster of any size and cloud offering for BigInsight ( either as PaaS, SaaS, IaaS) helps to provide elasticity.
The above architecture really opens up un-explored opportunities without having to deal with a big time initial investment, changing business dynamics & analytics requirement , foremost without compromising on the control. Business can choose to experiment with setting up a data lake with a in-premise cluster , and let the usage of analytics evolve. As and when they are ready can provision a cloud for any specific analysis they prefer to do. ( Example Click data analysis for traffic generated on the web for retailers during the holiday season or multi-facet clustering for a new promotion by a financial hub).
While the SQL on Hadoop has evolved for structured data , use of existing MPP/In-memory technologies as accelerator for operational reporting is optional. Will publish my thoughts on data flow and governance model for data lake in my next blog.

Very informative. I love how you deliver your thoughts. Hope to learn a lot from you about Big Data. Kudos!
Thank you for a succinct explanation on Data Lakes, just now being exposed to this concept